就在刚刚,百度重磅开源了最强多模态文档理解模型:PaddleOCR-VL。
仅 0.9B 参数,刷新 OmniBenchDoc 纪录,登顶全球第一,四大核心能力实现全线了 SOTA,全面超越 GPT-4o、Gemini-2.5 Pro 以及 MinerU2.5、dots.ocr 等模型。
GitHub:
在 AI 时代,文档数据结构化的重要性不言而喻,但各类 OCR 工具的识别精度却参差不齐。
一些文档中存在复杂的表格、数学公式或多栏排版,传统 OCR 工具识别出来的内容经常错乱,最终还要手动整理。
PaddleOCR-VL 模型问世后,彻底解决了这一痛点。
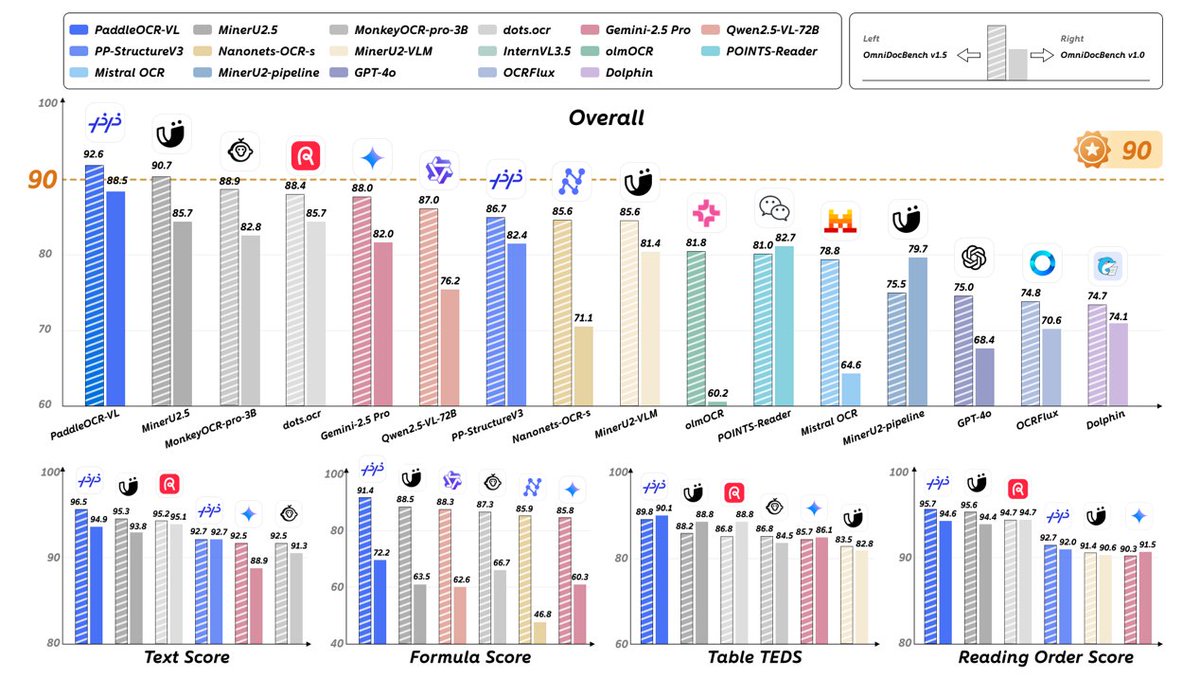
作为文心 4.5 最强衍生模型,在全球权威评测榜单 OmniDocBench v1.5 中,以 92.6 高分取得综合性能全球第一的成绩,推理速度较 MinerU2.5 提升 14.2%,较 dots.ocr 提升 253.01%。
这次不再只是简单的文字识别,而是真的能 “读懂” 文档结构,无论是学术论文、多栏报刊还是技术报告,PaddleOCR-VL 都能智能理解文档布局,自动按正确顺序整理内容。
同时精准提取文档里的表格、数学公式、手写笔记、图表数据等复杂内容信息,并将它们转换为可直接使用的结构化数据。
除此之外,还支持 109 种语言识别,覆盖中文、英语、法语、日语、俄语、阿拉伯语、西班牙语等多语种场景,大幅提升了模型在多语言文档中的识别处理能力。
目前模型已经开源,并支持多种部署方式,还可以在 HuggingFace 上直接体验。
在线体验:

@PaddlePaddle @Baidu_Inc
